

Special Articles on Private Cross-aggregation Technology—Solving Social Problems through Cross-company Statistical Data Usage—
Solving Social Problems through Cross-company Statistical Data Usage—Overview of Private Cross-aggregation Technology—
Security Privacy Protection Data Usage
Kazuma Nozawa, Tomohiro Nakagawa, Kazuya Sasaki and Masayuki Terada
X-Tech Development Department
Abstract
An effective means of solving social problems is to use the data held by individual companies in a cross-company manner with the aim of obtaining a panoramic view of phenomena occurring in society. On the other hand, the creation of new rules governing the protection of privacy by data providers is progressing in Japan and other countries, which reflects the importance of using data while protecting individual privacy. This article provides an overview of private cross-aggregation technology that creates cross-company statistics while protecting private information. With this technology, the statistical use of cross-company data will make it possible to grasp phenomena from a new perspective previously not possible, leading to more effective problem solving.
01. Introduction
-
Decision-making based on data is coming to be widely adopted in ...
Open

Decision-making based on data is coming to be widely adopted in society and the use of data in solving a variety of social problems is increasing in importance. At NTT DOCOMO, for example, operational data from the mobile terminal network*1, Note is being used to estimate population statistics and contribute to the formulation of disaster prevention plans such as measures for stranded commuters at the time of a disaster [1]. Obtaining an accurate understanding of a phenomenon using data is therefore expected to achieve more efficient problem solving. However, when focusing on a particular problem and thinking how best to solve it, relying only on the data held by a single company may result in a one-sided view of that phenomenon. In such a case, using data stored by different companies in a cross-company manner will enable social phenomena to be grasped from a composite and comprehensive perspective [2].
However, in response to these heightened expectations of the benefits that can be obtained through data usage, the creation of new rules related to privacy protection targeting data providers is progressing in Japan and other countries. In the European Union (EU), General Data Protection Regulation (GDPR)*2 [3] was put into effect in 2018, reflecting progress in the development of a legal system governing the protection of personal information. Meanwhile, in the United States, application of the California Consumer Privacy Act (CCPA)*3 [4] began in the state of California in 2020. In Japan, as well, the Amended Act on the Protection of Personal Information [5] was put into effect in April 2022 with the aim of handling personal data in a more appropriate way. Companies involved in data usage have the responsibility of observing these rules toward the safe and secure use of data. Furthermore, in addition to such legal compliance, it is important that these companies protect privacy and use data in a manner that can give the individual behind that data peace of mind. For example, in the 2022 U.S. national census, the United States Census Bureau adopted a mathematically rigorous privacy protection index called differential privacy*4. In the past, stopgap privacy protection measures such as data swapping*5 had been used, but an increase in the amount of data along with a jump in the processing power of computers meant that the threat of reconstruction attacks that are capable of recovering some or all of the original data could no longer be ignored [6][7]. In this way, it is becoming increasingly important to protect private information in data usage.
Given that laws are being complied with and an individual’s private information is being protected, consideration can then be given to the processing of data converted to statistics that cannot re-identify individuals as an actual method of using data (hereinafter referred to as “statistical data usage”). Statistics are data obtained, for example, by estimating common elements from the information of multiple individuals in which any correspondence with those individuals is excluded. Such statistical data usage is common within a single company (see [8], for example), but it is not so easy to do so across more than one company. The reason for this is that relevant laws must be observed and statistics must be created without disclosing private information even in the process of transferring data between companies. To perform cross-company use of statistical data, it is necessary to solve the issue of privacy protection in the process of creating output data and the issue of privacy protection in that output data.
The issue in protecting privacy in the process of creating output data is that the process of inputting and aggregating data to create statistics can disclose private information including personal information related to data input to another company or third party. For example, to create statistics using the data of one’s own company and the data of other companies, it is necessary to disclose one’s own data to those other companies, but private information including personal information in one’s own data is not protected.
In addition, the issue in protecting privacy in output data is that private information can be read from that output data aggregated and processed in a cross-company manner. It has been pointed out that private information can be infringed upon even for aggregated results that appear to be safe by using combinations of aggregated results and background knowledge [9]. Accordingly, to use cross-company statistical data while protecting private information, the protection of private information in output data is absolutely essential.
In short, for companies that seek to participate in cross-company statistical data usage, there is need for technology that can solve both of the above issues to enable statistical data usage.
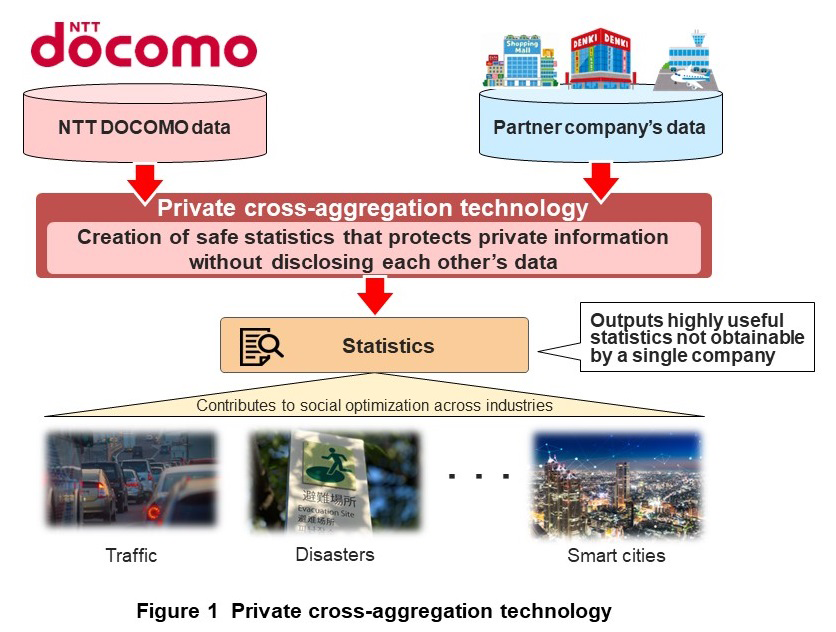
Against the above background, NTT DOCOMO, in cooperation with Nippon Telegraph and Telephone Corporation (NTT), developed private cross-aggregation technology that enables statistical data usage across data held by multiple companies (Figure 1). With this private cross-aggregation technology, data held by multiple companies (such as NTT DOCOMO data and the data of a partner company) is processed at each company so that individuals cannot be re-identified (so that no information is linked to an individual). Statistics can then be created from the data while technologically guaranteeing that no data is disclosed between them, that is, while automatically processing the data so that it is never subject to human viewing throughout the process. In addition, envisioning that this technology will one day find widespread implementation in society, the usefulness of statistics created in this manner was also tested. Once legal compliance has, of course, been met and personal information protected, expanding the domain of data usage from within the company to between companies should make it possible to obtain totally new perspectives that could not be obtained from the data of a single company. This article summarizes the requirements for using statistical data across companies, describes the policies for meeting those requirements, and presents an overview of private cross-aggregation technology.
- Operational data from the mobile terminal network: Generic name of data in the process of providing telecommunications services.
- GDPR: A protection regulation regarding the handling of personal information applied in the EU and European Economic Area. It is also applicable to the acquisition and movement of personal information.
- CCPA: A state statute enacted to protect the privacy of residents in the state of California, United States.
- Differential privacy: An index that quantitatively measures the strength of privacy protection. It was created with the aim of guaranteeing privacy protection even against attackers having specific background knowledge and attacking ability. A protection technique using differential privacy has been adopted in the U.S. national census.
- Data swapping: A technique that exchanges attribute values in a data set in a way that is inconsistent with the original records.
-
Based on the issues described above, the following summarizes the requirements ...
Open
Based on the issues described above, the following summarizes the requirements for using cross-company statistical data and the policies for satisfying those requirements and describes the use of this technology in solving social problems.
2.1 Requirements for Using Cross-company Statistical Data
We here define the privacy and security requirements that must be satisfied in the use of cross-company statistical data. In general, creating statistics from the data held by two companies, for example, requires at the least that one of those companies provide data to the other company and that a secure aggregation process be performed. In this case, if the company receiving that data can confirm its content, input data would be disclosed to that company (or a third party). Moreover, if any correspondence with actual individuals is not excluded from the data output after data linking, private information in that data output would not be protected.
Even if safe and secure output data could be obtained in some way, there must be some usefulness to that data if it’s to have any value. It is also desirable that the usefulness of that data created across companies lie in the value of data usage that could not be obtained by a single company. It is therefore not enough to just create safe and secure statistics—it is also necessary to evaluate its usefulness. The requirements that must be satisfied in the use of cross-company statistical data are listed below.
- Before data linking, the data must be processed so that no individuals can be re-identified, and during data linking, one’s own company data must not be disclosed to another company.
- Private information in output data after data linking must be protected.
- Value that could not be obtained by a single company must be provided from the statistics created across companies.
2.2 Approach to Satisfying Privacy and Security Requirements
The following describes policies for satisfying the requirements described above. The appropriate combination of the processes described in 1) – 4) below can satisfy those privacy and security requirements.
1) De-identification Process
It was decided to adopt the hash function*6 to transform the data into a form in which no individuals could be re-identified before data linking. With the hash function, salt*7 can be added to the data before calculating a hash value (hereinafter referred to as “de-identification hash”) in an operation called hashing*8. After hashing, destroying the salt transforms the hash value into an irreversible de-identification hash.
2) Secure Aggregation Process Using Homomorphic Encryption Technology
Next, it was decided to adopt homomorphic encryption technology [10] to prevent one’s own company data from being disclosed to another company during data linking. This technology makes it possible to perform computations on data such as data aggregation between companies while the data is in encrypted form. Homomorphic encryption technology guarantees confidentiality in that only approved entities can access the information in question, and since this protects private information from being observed by the company performing the data aggregation, it acts as a solution to the issue of how to guarantee privacy in the process of creating output data.
3) Disclosure Limitation Process Through Noise Addition*9 Based on Differential Privacy
However, the requirement of having to solve the issue of guaranteeing privacy in output data cannot be satisfied solely by homomorphic encryption technology. Here, noise addition based on differential privacy is useful as a countermeasure to the problem of guaranteeing privacy in output data. Differential privacy is an index that quantitatively measures the strength of privacy protection, and as such, it was created to guarantee safety even against attackers having specific background knowledge and attacking ability [9]. While past indices exhibited some degree of guaranteeing safety against specific attackers and preconditions, differential privacy is an index aiming for general-purpose safety. Encrypting the data of each company by homomorphic encryption, performing a secure aggregation process on that data in encrypted form, and adding noise based on differential privacy provides a solution to the issue of how to guarantee privacy in output data. If noise addition based on differential privacy were to be performed on data in plaintext form, aggregation results before noise addition could be understood, which raises concerns that private information could not be protected. It is therefore essential that the entire series of data processes from input to output be performed in encrypted form to guarantee confidentiality.
4) Implementing Data Processing in a TEE
Appropriately combining and correctly performing homomorphic encryption technology and noise addition technology based on differential privacy resolves the issues of guaranteeing privacy in the process of creating output data and guaranteeing privacy in the output data. However, there is always the possibility of an error occurring in data processing, so a countermeasure to such an occurrence must be devised. In the event that homomorphic encryption and noise addition based on differential privacy is not correctly performed (due, for example, to altered software), there is the possibility that private information will not be protected in either input or output. By therefore guaranteeing integrity*10, which is the property by which software has not been altered, correct execution of processing as expected can be technically guaranteed. Specifically, it is the policy of implementing the series of data processes consisting of homomorphic encryption and noise addition based on differential privacy in a Trusted Execution Environment (TEE). A TEE is a technology that places data in a reliably isolated area and executes and completes data processing within that area. In particular, integrity can be guaranteed by executing data processing within a hardware-based isolated area. Details of this technology are provided in another special article in this issue [14].
2.3 Private Cross-aggregation Technology
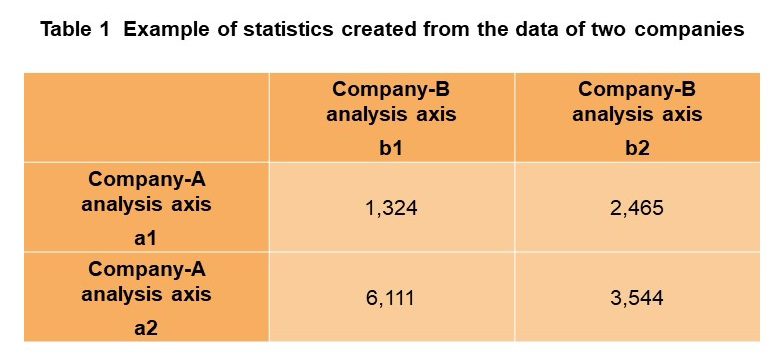
Based on the policy described above, NTT DOCOMO developed private cross-aggregation technology that guarantees both confidentiality and integrity when using statistical data across companies. Private cross-aggregation technology creates statistics by performing (1) a de-identification process (processing that puts data into a state in which no individuals can be identified), (2) a secure aggregation process, and (3) a disclosure limitation process all in a TEE. The de-identification process (1) performs an irreversible conversion of IDs held by each company and puts data into a state in which no individuals can be re-identified. Specifically, after adding salt to IDs within a TEE and obtaining de-identification hashes using a one-way function, the TEE technically guarantees the integrity of the process including destruction of that salt. Here, each company encodes its de-identification hashes using a separate encryption key. The secure aggregation process (2) and disclosure limitation process (3) combine homomorphic encryption technology and noise addition technology based on differential privacy in a TEE. The user can obtain statistics in which private information is protected without mutually disclosing de-identification hashes through these processes. In addition, input data of this technology consists of ID lists extracted on the basis of specific conditions set by each company. The de-identification process (1) puts these ID lists into a state in which no individuals can be identified (a state with no personal information), and the secure aggregation process (2) and disclosure limitation process (3) output the number of elements for each common set of de-identification hashes held by each company. In this regard, the extraction conditions of each company change according to the analysis axis*11, so cross tabulation (Table 1) can be created by repeatedly executing this technology. Cross tabulation refers to a table that sets and aggregates two or more indices in rows and columns. Cross tabulation created by this technology consists of each company’s analysis axes indicated along the top and side of the table.
Private cross-aggregation technology satisfies defined requirements by appropriately combining homomorphic encryption, noise-addition technology based on differential privacy, and a TEE. It can therefore achieve cross-company statistical data usage while protecting personal information.
2.4 Using This Technology to Solve Social Problems
To evaluate the usefulness of private cross-aggregation technology, the values of output data created across companies must be examined. It was therefore decided that NTT DOCOMO would conduct a demonstration experiment in collaboration with partner companies to assess whether the requirement that value that could not be obtained by a single company must be provided from the statistics created across companies is satisfied. Specifically, we joined up with Japan Airlines and JAL CARD to conduct a demonstration experiment on improving the customer experience and solving a social problem through the smooth use of airline travel [11]. In this experiment, we took information on reservation data for domestic airplane tickets held by Japan Airlines and combined it with operational data (including mobile-terminal location data) of the mobile phone network held by NTT DOCOMO after putting the data held by each company into a state in which no individuals at each company could be re-identified (a state with no personal information) using private cross-aggregation technology. In this way, we were able to create statistics related to the movement of passengers up to their arrival at the airport prior to boarding. It was shown through this experiment that a new perspective that could not be obtained by a single company could indeed be obtained through the use of these statistics thereby demonstrating the usefulness of private cross-aggregation technology. Going forward, the plan is to apply the results of this demonstration experiment to measures and policies at Japan Airlines and JAL CARD and to further specify and clarify the value created by private cross-aggregation technology by quantitatively evaluating the effect of those measures and policies. Details of this demonstration experiment are provided in another special article in this issue [12].
- Hash function: A type of one-way function in which obtaining the input character string from the output character string is impossible. It is a function that converts a character string of arbitrary length into a fixed-length character string (hash value). A property of the hash function is that the same character string is output for identical inputs.
- Salt: Random data added to the input of the hash function when hashing (see *8) data.
- Hashing: The process of computing a hash value from the original data using a hash function. Since the salt used for hashing is destroyed after the hashing process, it is impossible to compute the original data from the hash value.
- Noise addition: The process of adding random numbers to aggregate tables to protect private information in output data.
- Integrity: The property by which software or data has not been altered.
- Analysis axis: The headers of the rows and columns of cross tabulation determined by the data held by each company.
-
This article presented an overview of private cross-aggregation technology ...
Open
This article presented an overview of private cross-aggregation technology that achieves cross-company usage of statistical data. Private cross-aggregation technology enables cross-company usage of statistical data while protecting private information by appropriately combining homomorphic encryption technology and noise-addition technology based on differential privacy to process data that has been placed into a state in which no individuals can be re-identified (a state with no personal information) through a de-identification process. These processes are all performed within a TEE.
Other special articles in this issue provide a detailed description of private cross-aggregation technology, describe and evaluate the platform design of private cross-aggregation, and evaluate the usefulness of using this platform in collaboration with partner companies [12]–[14].
By achieving both data usage and protection through private cross-aggregation technology and solving diverse social problems, we hope to create a virtuous cycle that returns the benefits of data usage to society and that promotes the further development of society and industry.
-
REFERENCES
Open
- [1] M. Terada, H. Kawakami, I. Okajima, T. Shinozaki and A. Sakashita: “Initiatives toward Practical Use of Mobile Spatial Statistics,” Journal of Digital Practices, Vol. 6, No. 1, pp. 35–42, Jan. 2015 (in Japanese).
- [2] Organisation for Economic Co-operation and Development (OECD): “OECD Big Data White Paper—Data-driven Society of the Future,” Akashi Shoten, 2018 (in Japanese).
- [3] EUR-Lex: “Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance),” Apr. 2016.
 https://eur-lex.europa.eu/eli/reg/2016/679/oj
https://eur-lex.europa.eu/eli/reg/2016/679/oj - [4] California Legislative Information: “1.81.5. California Consumer Privacy Act of 2018 [1798.100 - 1798.199.100].”
http://leginfo.legislature.ca.gov/faces/codes_displayText.xhtml?lawCode=CIV&division=3.&title=1.81.5.&part=4.&chapter=&article= - [5] e-Gov: “Act on the Protection of Personal Information (Act No. 57 of 2003)” (in Japanese).
https://elaws.e-gov.go.jp/document?lawid=415AC0000000057 - [6] S. Garfinkel, J. M. Abowd and C. Martindale: “Understanding Database Reconstruction Attacks on Public Data,” ACM Queue, Vol. 16, No. 5, pp. 28–53, Oct. 2018.
- [7] M. Terada: “Differential Privacy Basics and Trends,” IPSJ Magazine, Vol. 61, No. 6, pp. 591–599, May 2020 (in Japanese).
- [8] NTT DOCOMO: “Mobile Spatial Statistics” (in Japanese).
https://mobaku.jp/ - [9] M. Terada: “What is Differential Privacy?”, Systems, Control and Information, Vol. 63, No. 2, pp. 58–63, 2019 (in Japanese).
- [10] J. Sakuma and W. Lu: “5. Activities toward Practical Use of Secure Computation Technology Using Homomorphic Encryption,” IPSJ Magazine, Vol. 59, No. 10, pp. 898–903, 2018 (in Japanese).
- [11] Japan Airlines, JAL CARD, NTT DOCOMO: “Japan Airlines, JAL CARD, and NTT DOCOMO Begin Demonstration Experiment of Cross-company Data Usage Using “Private Cross-aggregation Technology” to Improve the Customer Experience and Solve a Social Problem—First Initiative in Japan Using Statistical Data Created Without Mutually Disclosing the Data Held by Each Company,” Oct. 2022 (in Japanese).
 https://www.docomo.ne.jp/binary/pdf/info/news_release/topics_221020_00.pdf (PDF format:0)
https://www.docomo.ne.jp/binary/pdf/info/news_release/topics_221020_00.pdf (PDF format:0) - [12] K. Onoda et. al: “Utilizing Cross-company Statistical Data through Use of a Private Cross-aggregation Technology—Initiatives to Improve Customer Experience and Solve Social Problems—,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023.
https://www.docomo.ne.jp/english/corporate/technology/rd/technical_journal/bn/vol25_1/004.html - [13] K. Nozawa et al.: “Technique for Achieving Privacy and Security in Cross-company Statistical Data Usage,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023
https://www.docomo.ne.jp/english/corporate/technology/rd/technical_journal/bn/vol25_1/002.html - [14] K. Hasegawa et al.: “Guaranteeing Integrity in Private Cross-aggregation Technology,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023.
https://www.docomo.ne.jp/english/corporate/technology/rd/technical_journal/bn/vol25_1/003.html
- Note: A generic name given to data generated in the process of providing telecommunications services, which is used in Mobile Spatial Statistics. Operational data includes location data of mobile phones and other devices used by subscribers and subscriber attribute data. Definitions of these terms can be found in Mobile Spatial Statistics Guidelines at the following link.
https://www.docomo.ne.jp/english/binary/pdf/service/world/inroaming/inroaming_service/Mobile_Spatial_Statistics_Guidelines.pdf (PDF format:73KB)

