

Special Articles on AI for Customer Support in Diverse Fields
Improvement of AI Recommendations at Shops and on the Web
Recommendations Learning to Rank GNN
Kenichiro Miyaki and Masato Hashimoto
Service Innovation Department
Abstract
NTT DOCOMO has been providing recommendations for a variety of services at shops or on the Web, but many such recommendations consist of uniform solicitations for any customer resulting in proposals that lack appeal. To propose services that are more appealing to the customer, NTT DOCOMO has developed AI technology that grasps the needs of individual customers and ranks a variety of services in an integrated manner. This approach has made it possible to make more convincing recommendations for the customer, improve the degree of customer satisfaction, and raise the subscription rate.
01. Introduction
-
NTT DOCOMO provides recommendations*1 and information ...
Open

NTT DOCOMO provides recommendations*1 and information regarding its services at a variety of customer touchpoints including the Web, shops, mobile apps, and social media. Such a diversity of touchpoints can help provide new value to customers and obtain useful feedback from them while enabling communications personalized for each and every customer.
In recent years, NTT DOCOMO has been treating the further improvement of customer satisfaction at such touchpoints as an important management issue and has undertaken a number of initiatives to that end. One of these is improvement of its recommendation system. A recommendation system is a technological platform for making individual proposals regarding content, products, services, information, etc. tailored to customer needs. Introducing a recommendation system at customer touchpoints makes it possible to provide services from the customer’s perspective taking into account the customer’s characteristics and demands. This, in turn, is expected to improve customer satisfaction at customer contact points.
On the other hand, a certain amount of time has passed since the development of the existing NTT DOCOMO recommendation system, and changes in Key Performance Indicators (KPIs) that a recommendation system should achieve have not been addressed and the incorporation of new technologies has been insufficient. As a result, optimizing recommendations and improving their accuracy have been lacking. In addition, problems associated with the structure of the overall system have created a variety of issues such as high operating costs. Against this background, NTT DOCOMO undertook large-scale improvements with the aim of solving those issues.
The new recommendation system introduces state-of-the-art technology in the form a Graph Neural Network (GNN)*2 and incorporates a function for appropriately measuring the affinity between a customer and a service. In this way, NTT DOCOMO has constructed a recommendation system from the customer’s perspective.
This article first presents an overview of the existing recommendation system (hereinafter referred to as “old recommendation system”) and associated issues and then focuses on specific techniques applied to the new recommendation system.
- Recommendations: Proposals regarding a product, content, etc. tailored to the user.
- GNN: A neural network designed to handle graph structures. A type of machine learning based on network theory. It has found success in many application fields including social-network analysis, prediction of chemical molecules, and recommendation systems and is known to be a powerful algorithm for modeling complex relationships in graph data.
-
2.1 System Overview
Open
The old recommendation system is configured such that the recommendation system for each media is completely independent of each other with no common input/output section. However, the recommendation systems in each media have similar processing sections, which are broadly divided into two processing sections as shown in Figure 1. The first one is the processing section for extracting customers targeted for recommendations for each service and the second one is the processing section for determining recommendation priority for each customer. These two processing sections have a mixture of manual processing sections and AI-based automatic processing sections. The existence of manual processing sections here is a distinctive feature of the old recommendation system.
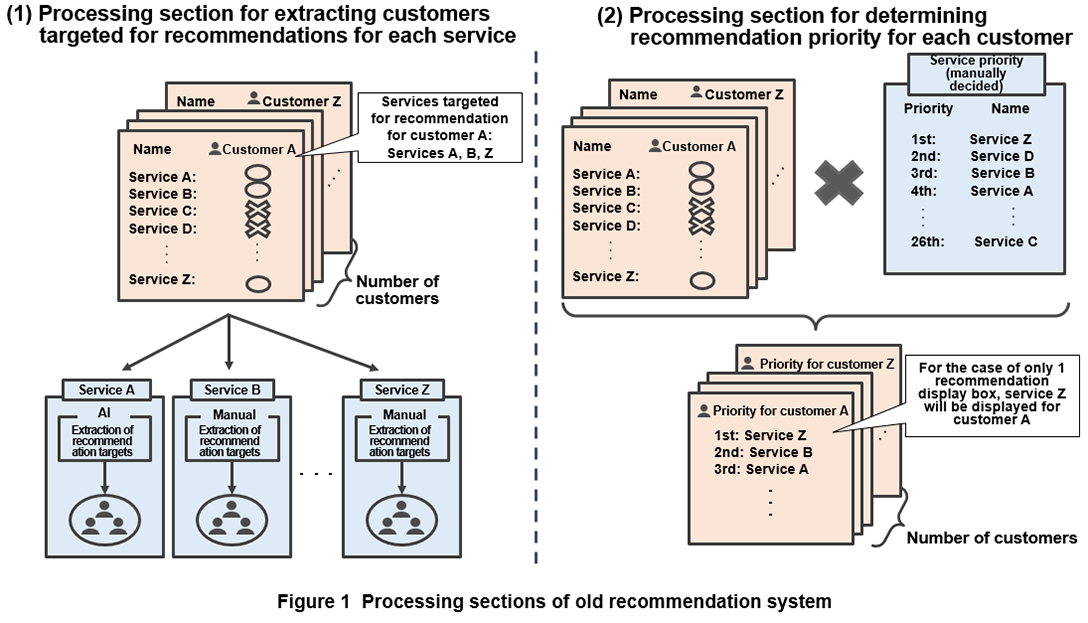
2.2 Issues
The old recommendation system has the following three issues.
1) Reduction of Work and Operation Costs
Since a recommendation system is constructed for each media, work and operation costs are incurred at an amount commensurate with the number of media. Additionally, the existence of manual processing sections generates significant cost related to human labor. Considering operations over the long term, these costs must be reduced and improvements made.
2) Unification of Recommendations across Media
Since each media is completely independent of each other, the content of the recommendations is not shared. This prevents recommendations across different media from being unified, and if the customer should visit multiple media, there is the possibility that different services will be recommended. This makes the services that should be recommended to the customer somewhat ambiguous, which may lead to a drop in customer satisfaction.
3) Optimization of Recommendations to Meet the Demands of Each Customer
In addition to the old recommendation system described above, recommendation systems in general have to deal with constraints in the display section of each media. Consequently, in the case of multiple services targeted as recommendations for a customer, it may be necessary to narrow down the number of recommendations. However, as shown in Fig. 1 (2), the narrowing down method used in the old recommendation system is to apply a set of service priorities applicable to all customers and to then make recommendations starting with high-priority services. As a result, if multiple services become targets of recommendation for individual customers, the process of narrowing down those services to a previously defined number prevents the creation of a priority list that reflects a customer’s demands and characteristics.
The new recommendation system introduced in this article addresses these three issues.
-
3.1 System Overview
Open
We constructed a new recommendation system to solve the above three issues in the old recommendation system. As described above, these three issues are (1) reduction of work and operation costs, (2) unification of recommendations across media, and (3) optimization of recommendations to meet the demands of each customer. To solve issues (1) and (2), we developed a recommendation system that eliminated manual processing sections through system consolidation and the introduction of AI and constructed an infrastructure that enabled output results to be shared by different media (Figure 2). Additionally, to solve issue (3), we developed AI for establishing the priority of services to be recommended to each customer from the customer’s perspective and introduced it into the system (Figure 3).
The elemental technologies adopted to solve these issues are described below.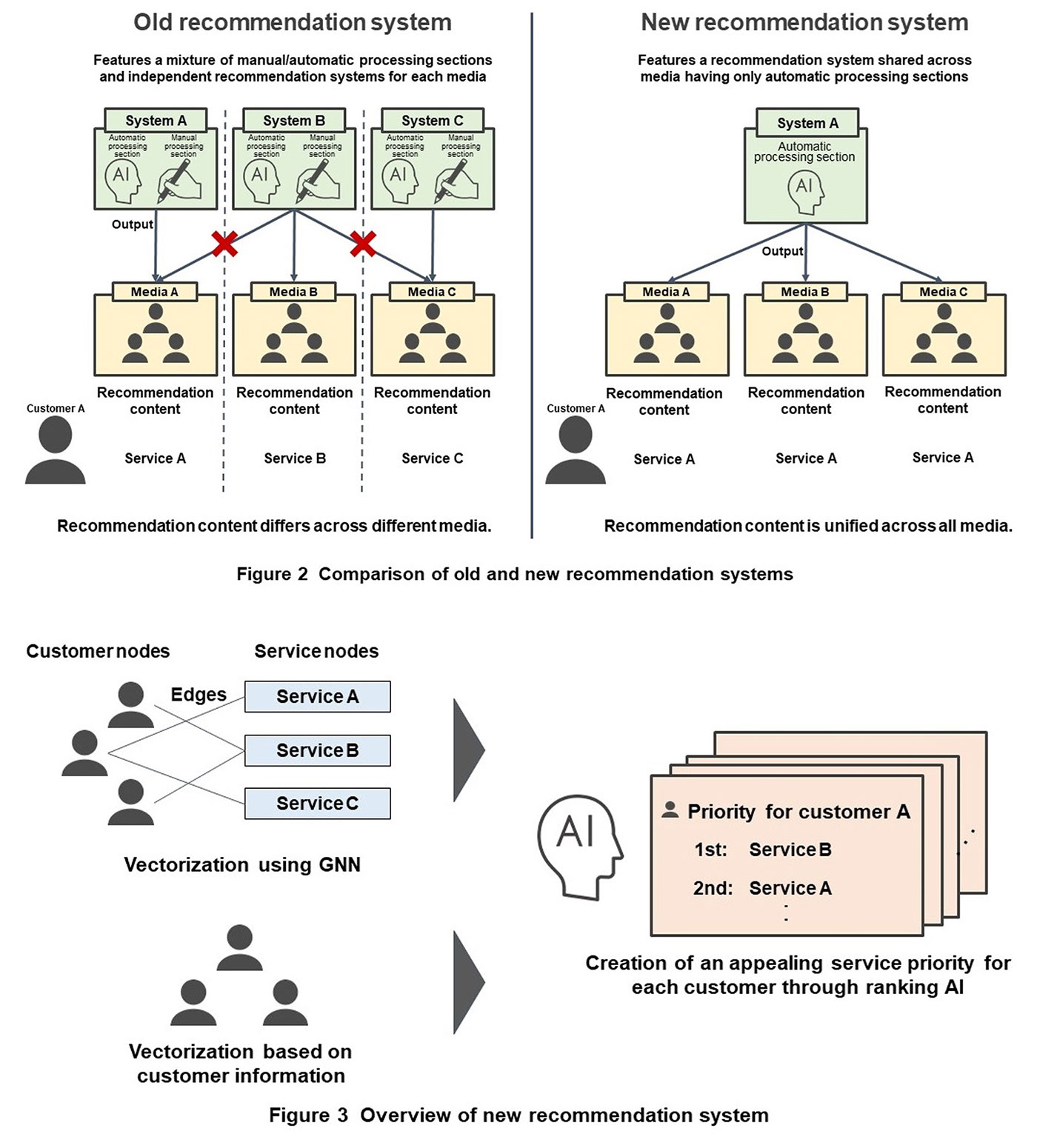
3.2 Elemental Technologies
1) Service Vectorization
(a) Overview
We applied vectorization to services targeted for recommendations. Vectorization refers to a technique that converts information such as service characteristics or customer usage trends into multidimensional values. The process of vectorization makes it possible to calculate the distance between vectors and measure the affinity between two vectors. At NTT DOCOMO, for example, there are a variety of services that target different customer profiles, and this vectorization technique enables the affinity between services to be expressed in terms of numerical values. Additionally, the fact that the distance between services corresponding to the same customer profile will be small while that corresponding to different customer profiles will be large makes it possible to check whether any affinity exists between certain services.
(b) Adoption of GNN using a heterogeneous graph
At NTT DOCOMO, we adopted GNN as a technique for achieving service vectorization. The data handled by the GNN technique is called a graph*3, which consists of node*4 and edge*5 elements. An AI neural network system that handles such a graph is generally called GNN. In the new recommendation system, customers and services are expressed as nodes with each referred to as customer nodes and service nodes (Fig. 3). In addition, the state in which a customer is subscribed to a service is expressed by setting an edge between that customer node and service node. In short, the graph of the new recommendation system is expressed as two types of nodes—customer and service—and as edges that connect them. A graph expressed as multiple types of nodes (or edges) is called a heterogeneous graph. The new recommendation system uses a heterogeneous graph.
(c) Definition of initial vectors
Next, we define an initial vector for each service node. There are two methods that can be used here to set an initial vector: a method that applies a vector configured with a random value and a method that applies a previously created vector that characterizes the node. The new recommendation system applies the former method to service nodes and the latter method to customer nodes. The latter method, in particular, uses a vector based on subscription information that has been subjected to anonymization*6. The reason for applying the former method to service nodes is that services targeted for recommendations have the possibility of changing at anytime, so there is a need for responding to such changes in a sequentially flexible manner. The graph and initial vectors of each node defined as described above are input into the GNN.
(d) Training by the link prediction problem*7
A GNN learns whether there is an edge (link) between two nodes. This type of learning method is generally called the link prediction problem. The distance between the vectors possessed by two specific nodes determines whether an edge exists between those nodes. If the distance is equal to or greater than a certain threshold value, an edge is determined to exist, and if it is less, no edge is determined to exist. This calculation for determining the existence of an edge is performed after the vector of each node is weighted and updated considering the vectors of neighboring nodes via edges. Training is performed repeatedly while updating weights and evaluating the accuracy of edge-existence determination until weighting is achieved that correctly determines whether an edge exists.
In this way, the vector of each node that has been weighted and updated considering neighboring nodes takes on a property that considers usage trends (graph structure). In other words, the vector distance for services whose user attributes are similar will be small while that for services whose user attributes differ will be large. In particular, the vector of a service obtained by training through the link prediction problem will grasp the features of that service, which will be useful in subsequent recommendation processing.
2) Customer Vectorization
Customer vectorization is performed using anonymized customer information and service usage history. There are mainly two methods for doing this: one that quantifies gender, age group, and subscription information in the form of a vector and the other that expresses affinity scores between the customer and recommended services in the form of a vector. Combining these two types of vectors gives a single vector for each customer. It can be said that this customer vector holds features such as attributes and tendencies for each individual customer.
3) Ranking Based on Affinity through Vectorization
Which services should be prioritized and recommended to each customer is determined on the basis of affinity between the two types of vectors described above (service vector and customer vector) (Fig. 3). This type of prioritizing is called ranking and the technique for learning ranking order is called learning to rank*8. Given all combinations of customers and services, this technique learns by outputting a high ranking for any combination in which a subscription exists and a low ranking if not.
After completing this learning process, the top five services ranked by AI for each customer are linked to each media as recommendation output.
3.3 Expected Effects
Introduction of the new recommendation system is expected to have the following effects. For issue (1), the new recommendation system can reduce manual work and operation costs by consolidating the recommendation systems that had been established independently for each media. For issue (2), it can eliminate the possibility of issuing different recommendations across different media and improve the user experience by unifying recommendations across all media. Finally, for issue (3), it can automate the prioritizing of services while considering limitations on the number of recommendations that can be displayed on each media and it can provide recommendations from the customer’s perspective thereby improving customer satisfaction.
- Graph: A set of nodes and edges.
- Node: One element making up a graph. An object. In this article, a node means a customer or service.
- Edge: One element making up a graph. A link connecting a pair of nodes. In this article, given that a certain customer has contracted for a certain service, an edge is defined for that customer node and service node.
- Anonymization: A processing technique that puts personal data into a state in which that person cannot be identified.
- Link prediction problem: In graph analysis, a task that estimates whether an edge exists between specific nodes.
- Learning to rank: Generic term for AI algorithms that learn and infer data ranking.
-
This article outlined the issues affecting NTT DOCOMO’s ...
Open
This article outlined the issues affecting NTT DOCOMO’s old recommendation system and described a recommendation system having a new mechanism for solving those issues. Going forward, we will work on improving the accuracy of the new system by performing comprehensive evaluations as needed to evaluate not only customer satisfaction but also the subscription rate and retention rate of each service. At NTT DOCOMO, we plan to continue our efforts in developing new technologies and systems with the aim of providing an even better customer experience.

